Failure happens
Have you ever failed at something? Maybe you didn’t get that big promotion, or your project was a flop. Whatever it is, everyone experiences failure from time to time. And it sucks. But as Guy Winch, Ph.D. says in his article on failure, what matters is how you recover from failure.
Nobody is immune to failure; no one is perfect, no matter how hard they try. Even the most successful and seemingly invincible individuals have stumbled from time to time, reminding us all that no one is above failure. The question isn’t if you will fail again, but when.
Recovery matters

Major league athletes often employ fast recovery methods by visualizing their performance and instantly adapting their game plan. Take a cue from the pros: fast recovery practices make winners.
Waiting too long to come back from a failure can do far more harm than you would think. People around you notice, and all the great work you have previously done will be forgotten if you don’t know how to recover quickly from a failure. You will lose the chance to lead that next big project as they think you don’t have the capacity, they think there is something significant that is causing you to fail, so they lighten the load on you. You lose the chance to shine and show your true capabilities. The sooner you learn how to recover quickly from a misstep, the better off you’ll be in the end.
Not taking action and failing to learn from a failure can lead to missed opportunities down the road. Learning exactly what caused the failure and why is essential because learning from the causes of failure is a great way to become successful in the future. By taking time to understand the situation and determine what is causing the issues, you can learn and be prepared for similar issues in the future. You will now be able to spot mistakes and correct them before anyone else has a chance to know there was an issue.
Why am I writing about this? Because as it happens, the same is true of network connectivity for hybrid and remote workers. Fast learning is needed to overcome network failure.
Networks fail – Overcoming network failure matters
Failure to deliver packets happens across networks all the time. For the hybrid or remote worker, it is at is worst when they are on unreliable or congested Wi-Fi networks coupled with high bandwidth but low-quality broadband internet connections. Even the best networks drop some packets. Overcoming network failure needs to happen quickly.
In the blog “Hybrid Worker Network Performance – A Hard Nut to Crack” Manohar talks about the severe impact that packet loss can have on an application causing slowdowns that lead to loss of worker productivity and morale. In the blog “The Future of Remote Employee Productivity”, I mention preemptive and accelerated packet recovery.
Accelerated recovery
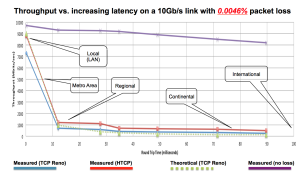 Here, I want to focus on one specific part of Cloudbrink’s patented “preemptive and accelerated packet recovery” – the accelerated recovery. When a packet is dropped, for whatever reason, the network and or application protocols often request a retransmission of the packet. However, a few dropped packets close together can cause protocol congestion controls to kick in, which slow down the rate at which packets are being exchanged. The problem is that with the adoption of the cloud, users are getting further away from their apps and data, connected via a collection of networks of varying reliability. So, when a packet is lost, the end systems have no idea where or why it was lost. When there are a few packet drops, they typically react assuming there is a network overload, so to stop the overload, the protocols slow things down. You can lose 95% of your available bandwidth with less than half of one percent of dropped packets. (See the graph from ESnet1)
Here, I want to focus on one specific part of Cloudbrink’s patented “preemptive and accelerated packet recovery” – the accelerated recovery. When a packet is dropped, for whatever reason, the network and or application protocols often request a retransmission of the packet. However, a few dropped packets close together can cause protocol congestion controls to kick in, which slow down the rate at which packets are being exchanged. The problem is that with the adoption of the cloud, users are getting further away from their apps and data, connected via a collection of networks of varying reliability. So, when a packet is lost, the end systems have no idea where or why it was lost. When there are a few packet drops, they typically react assuming there is a network overload, so to stop the overload, the protocols slow things down. You can lose 95% of your available bandwidth with less than half of one percent of dropped packets. (See the graph from ESnet1)
In the detailed whitepaper titled “An introduction to Cloudbrink and their technology,” there are references to several sources to explain the Cloudbrink technology. It notes that in 1984, J. H. Saltzer, D.P. Reed and D.D. Clark of M.I.T Laboratory for Computer Science published End-to-End arguments in Systems Design, which argued the need to properly trade end-to-end decisions with lower-level localized decisions. However, almost twenty years later, Tim Moors published A critical review of “End-to-end Arguments in system design”. In his review, Tim Moors made specific arguments for localized (per-hop) decisions, including:
- Localized error detection reduces the network load by reducing the distance that erroneous packets will propagate through the network.
- Localized error recovery to reduce the delay in delivering the packet with integrity; the propagation delay across a hop is likely to be smaller and less variable than the end-to-end propagation delay.
It is this localized detection recovery that delivers the accelerated packet recovery. In the design of the protocol, there is the ability to find dropped packets on a per-hop basis and retry them at the closest point. With the Brink FAST edges (Flexible Autonomous, Smart, and Temporary) having a global median of being less than 5ms from the user’s device, those lost Wi-Fi and broadband packets (when they are not recovered through the intelligent protocol – which is another topic in itself) are requested to be retransmitted almost immediately. The thousands of FAST edges available can do the same at any other segment of the traversed networks.
So yes, the network will occasionally fail, and packets will be dropped, but the recovery is so swift that the application knows nothing of it. Overcoming network failure has to be ultra-fast. Just like in life, it is important to recover quickly from failure when it comes along.
High-performance matters – high-performance requires overcoming network failure quickly
In summary – accelerated packet recovery is part of what makes Hybrid Access-as-a-service from Cloudbrink the highest-performing ZTNA solution in the market. It is the only ZTNA solution that was designed for the well-being of the hybrid workforce as well as the security needs of the company and the user. Other ZTNA solutions rely on end-to-end network and application protocols to recover packets taking hundreds of milliseconds to recover and causing the session to slow down. Employees don’t want frustratingly slow applications and data access in the name of security, they want to access their apps and data wherever they are in a fast, responsive way. Overcoming network failure quickly makes for happy remote employees.
Security matters too
Oh, and by the way, here at Cloudbrink, we care a lot about security In fact, as well as employing the latest TLS 1.3, using mutual authentication with continuous posture assessment, we deploy moving target defense (MTD) approaches to certificates and data paths – more on that in later blogs.
Looking for an ultra-fast ZTNA solution that overcomes network performance issues?
Click here to check out our ZTNA page.
Check out our whitepaper or webinar here.
Request a demonstration here.
- The following paper from Energy Sciences Network was foundational to the information on packet loss https://www.es.net/assets/pubs_presos/sc13sciDMZ-final.pdf