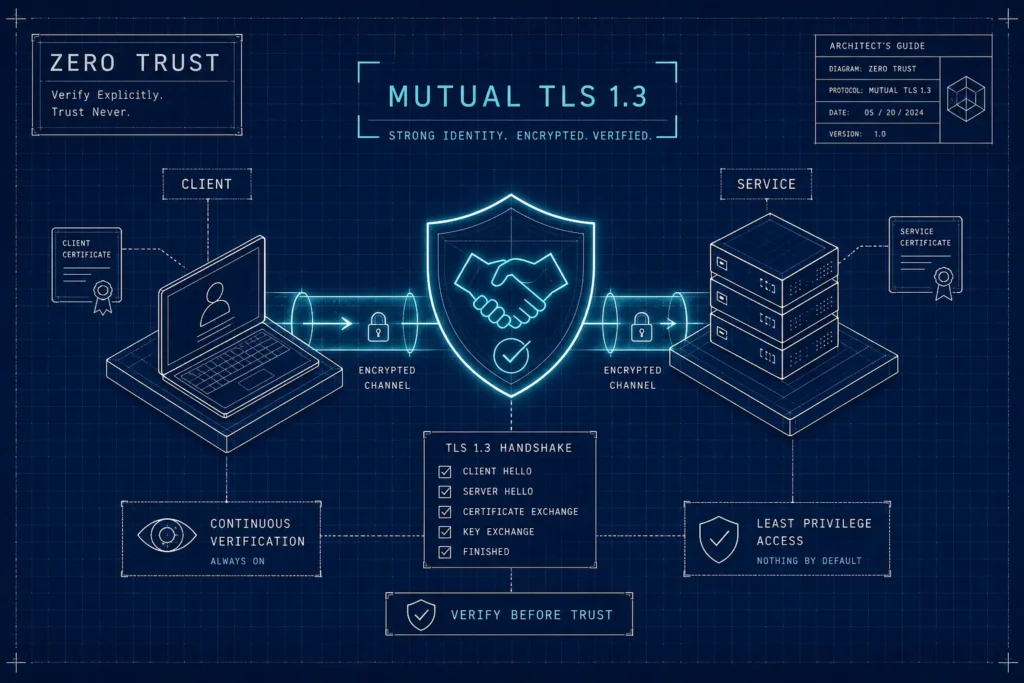
Most architectures encrypt traffic in transit. Far fewer verify both sides of the connection. Standard TLS proves the server is who it claims to be, but the client remains cryptographically anonymous at the transport layer. Implementing zero trust with mutual TLS 1.3 closes that gap: both parties present certificates, both verify the peer’s certificate chain, and neither side grants access based on network location alone. That structure treats authentication as a cryptographic contract on every connection, not a perimeter control applied once at the edge.
Platforms like Cloudbrink Personal SASE implement this model natively, combining mTLS-grade encryption with adaptive access policies so teams get bidirectional authentication without configuring every proxy and PKI pipeline themselves. For teams building from scratch, this guide covers each layer: PKI architecture, HSM integration, platform configuration, 0-RTT trade-offs, and the failure modes architects most often underestimate. The details are where implementations succeed or quietly fail.
Why Zero Trust with Mutual TLS 1.3 Starts at the Transport Layer
Zero trust requires continuous verification of every connection, not a one-time check at the perimeter. Standard TLS deployments authenticate only the server, leaving client identity unverified at the transport layer. Mutual TLS changes that: every service, workload, and user session carries a cryptographic identity tied directly to access policy. Decisions get made on verified certificate attributes, not inferred from IP ranges or session tokens.
In one-way TLS, the client verifies the server but the server has no cryptographic proof of who the client is. In mTLS, the server sends a CertificateRequest during the handshake and the client responds with its own certificate and a CertificateVerify message proving possession of the corresponding private key. The result is a session where both parties have proven identity through a trusted CA. Every service-to-service call, every user-to-service connection, carries provable identity that policy engines can actually enforce.
TLS 1.3 reshapes the handshake in ways that directly strengthen this model. After ServerHello, the server certificate, the CertificateRequest, and the client’s certificate response are all encrypted and invisible to passive observers. Certificate metadata no longer leaks in transit. The tighter 1-RTT structure also eliminates weak cipher suite negotiation entirely, so there is no accidental fallback to RSA key exchange or other deprecated mechanisms. When you are rolling mTLS across a large, mixed fleet, that matters.
Planning Your PKI Architecture for Enterprise mTLS
Scaling mTLS across hundreds of services requires more than issuing a few certificates manually. It requires a layered CA hierarchy, automated enrollment and renewal, and tight integration with identity and device management systems. Without that foundation, certificate sprawl and silent expiration become the dominant failure mode, not attackers.
The right CA hierarchy separates three layers: a root CA that stays offline and HSM-backed, intermediate CAs scoped by environment or workload type, and issuing CAs integrated directly with automation pipelines. This limits blast radius. If an issuing CA is compromised, it doesn’t invalidate the entire trust chain. For automation protocols, ACME and ACME-DA cover most cloud workloads and general-purpose issuance. Dynamic SCEP is the standard path for MDM/UEM-managed endpoints, including Windows, macOS, iOS, and Android. Platforms like EJBCA provide comprehensive protocol support (ACME, SCEP, EST, CMP, REST) for heterogeneous fleets, while HashiCorp Vault PKI fits well when certificate issuance is part of a broader secrets management workflow. If you want a practical discussion of why large organizations prioritize mTLS adoption, see why mTLS is important for organizations today.
Automating the Certificate Lifecycle
Certificate lifecycle automation has four stages, and all four must run without gaps. Issuance requires identity proofing and policy-gated enrollment. Distribution depends on endpoint type: MDM agents for devices, Kubernetes Secrets for workloads, workload controllers for cloud-native services. Renewal should happen pre-expiration via ACME or SCEP with no user action required.
Revocation must be immediate and automatic, triggered by offboarding or compromise events and propagated via CRL and OCSP. Integration with identity providers such as Okta and Microsoft Entra ID, and endpoint management platforms like Intune and Jamf, ensures that device offboarding triggers revocation as a system event rather than a manual ticket.
Because Cloudbrink rotates mTLS 1.3 certificates every eight hours, any stolen or exposed certificate has a very short useful life. That means an attacker cannot rely on long-lived credentials to maintain persistent access. It also supports Cloudbrink’s broader zero-trust model: access is continually revalidated rather than assumed for long periods.
Protecting Private Keys with HSMs and Cloud KMS
The entire mTLS security model rests on one assumption: private keys are controlled. If keys can be extracted from disk, containers, or config stores, certificate-based identity becomes as weak as any shared secret. The standard approach is to generate and store private keys inside an HSM or cloud KMS, exposing only a signing interface to the TLS terminator. The application never reads the raw key. It requests a signing operation, and the key material never leaves the protected boundary.
Choosing Between HSM and Cloud KMS
HSMs provide hardware-rooted key custody, FIPS 140-2/3 compliance, and non-exportable key guarantees. They are the right choice for CA root and intermediate keys, and for service identity keys in regulated environments where external key custody requirements apply. Cloud KMS offers easier lifecycle management, native cloud integration, and policy-based access controls, practical for service identities in cloud-native workloads where hardware custody isn’t mandated. The cleanest enterprise model puts root and intermediate CA keys in HSMs, service identity mTLS keys in HSMs or tightly controlled KMS, with no private key material written to disk or environment variables. For vendor-specific guidance on HSM-backed cloud KMS options, see the Cloud KMS HSM documentation for Google Cloud KMS.
The TLS terminator, whether NGINX, Envoy, HAProxy, or an application sidecar, needs a crypto interface to call the HSM or KMS for signing operations during the handshake. For on-premises HSMs that means PKCS#11, with the terminator configured to use an OpenSSL PKCS#11 provider rather than a file-backed key reference. In an NGINX configuration, this looks like setting ssl_engine pkcs11 and pointing ssl_certificate_key at a PKCS#11 URI instead of a PEM file. The certificate and public key live in the normal PKI store. The private key never leaves the HSM. Provider-based PKCS#11 integration is the safer path for TLS 1.3 specifically, since older engine-only setups have known compatibility gaps with TLS 1.3’s signature-based handshake authentication.
Deploying Zero Trust with Mutual TLS 1.3: Platform Configuration
Platform configuration is where implementation either holds together or quietly breaks down. The core pattern is consistent across platforms: present a server certificate, require a client certificate from a trusted CA, enforce TLS 1.3 as the minimum protocol version, and verify the peer certificate chain on both sides.
For NGINX, the key directives are ssl_client_certificate pointing to the CA that issued client certs, ssl_verify_client on enforcing hard rejection of unauthenticated clients, and ssl_protocols TLSv1.2 TLSv1.3. Setting verification to on rather than optional matters: optional pushes the rejection logic into application code, where it is easier to misconfigure. For HAProxy, verify required on the bind directive combined with ssl-min-ver TLSv1.3 in defaults achieves strict mTLS enforcement at the transport layer. Both proxies support presenting a client certificate to upstream services, enabling east-west mTLS between infrastructure components. For concrete configuration examples and TLS 1.3 tuning for NGINX, HAProxy, and Envoy, review a hands-on TLS 1.3 in production configuration guide.
Kubernetes and the 0-RTT Trade-off
In Kubernetes, the cleanest mTLS 1.3 architecture stores private keys in Secrets, mounts them into the proxy pod, and uses Envoy Gateway’s BackendTLSPolicy or Backend resources to bind trust anchors and client credentials to specific backend routes. Envoy handles certificate presentation and peer verification. The application receives traffic only after both sides have authenticated. Certificate rotation happens by updating the Kubernetes Secret, keeping the process infrastructure-native and auditable without manual key distribution.
TLS 1.3’s 0-RTT mode deserves specific attention. It allows a client to send early application data on session resumption, reducing round-trip latency. The trade-off is that early data is replayable: an attacker who captures a 0-RTT session can replay it against multiple server instances without triggering a full handshake. The safe default in mTLS deployments is to disable 0-RTT, or restrict it strictly to idempotent read operations. Do not place state-changing requests, authenticated actions, or authorization decisions in early data. TLS itself does not prevent cross-instance replay, so the protection burden falls entirely on the application layer if you enable it.
Failure Modes and Architectural Blind Spots in mTLS Zero Trust
TLS 1.3 and automated PKI answer specific, bounded questions: is the channel encrypted, and can both sides prove certificate possession? They do not answer the broader zero trust question of whether this authenticated requester should be allowed to perform this action right now. That distinction is where most mTLS implementations have gaps, and where architects need to plan explicitly.
Automation reduces manual error, but introduces its own failure modes. Certificates expire when renewal pipelines fail silently. Revocation is operationally hard at scale: CRL propagation has latency, OCSP responders become availability bottlenecks under load, and cached validation states can lag behind actual compromise events. Short-lived certificates narrow the exposure window but amplify the consequences of a missed renewal. The PKI trust anchors themselves are high-value targets; a compromised CA or enrollment agent can issue trusted credentials at scale, invalidating the identity model entirely. Monitoring certificate inventories, issuance anomalies, and renewal failure rates is the operational baseline for any PKI-backed zero trust architecture, not an optional enhancement.
TLS authenticates the transport peer and protects the session. It does not verify that the endpoint is healthy, uncompromised, or behaving within policy. A device with a valid client certificate that has been compromised will pass every TLS check. TLS also performs no fine-grained authorization at the application layer: that requires policy enforcement points, context-aware access controls, and integration with IAM systems. The practical implication is that architecting zero trust with mutual TLS 1.3 delivers a required control, not a complete one. It must be layered with endpoint posture checks, continuous identity verification, and application-layer authorization. Cloudbrink Personal SASE addresses this by combining mTLS-grade transport security with adaptive access policies and real-time identity verification, so zero trust enforcement doesn’t require individual teams to stitch together proxies, PKI pipelines, and posture systems themselves.
From Architecture to Deployment: What You Need Before Go-Live
The deployment checklist is straightforward in concept. Design a layered CA hierarchy with offline root and HSM-backed intermediates. Automate enrollment and renewal through ACME or SCEP, integrated with your identity provider and endpoint management platform. Protect private keys in HSMs or tightly controlled KMS with no export to disk or config stores. Configure platform-level client certificate enforcement with strict verification, not optional. Disable 0-RTT or gate it to idempotent requests only. Then layer authorization controls above the transport to close the gap that TLS cannot close on its own.
Before enabling mTLS in production, verify the full handshake end to end with openssl s_client -connect host:443 -tls1_3 and confirm the negotiated protocol, cipher suite, and client certificate presentation. Test revocation propagation under realistic latency conditions. Confirm that renewal failures generate alerts before certificates expire. Verify that offboarding workflows trigger automatic revocation rather than a manual ticket. These aren’t edge cases. They are the operational conditions that determine whether your mTLS zero trust architecture holds under real-world pressure. For the definitive TLS 1.3 specification, consult RFC 8446 (TLS 1.3).
When implemented correctly, zero trust with mutual TLS 1.3 becomes one of the most reliable controls in your architecture: bidirectional cryptographic identity at every connection, encrypted handshake metadata, and a protocol with no legacy cipher fallback paths. Skip any layer and the chain breaks where you least expect it, usually at 2 AM during an incident.
That’s why Cloudbrink builds mTLS 1.3 into the foundation of Personal SASE, not as an add-on. Every user, device, and connection is continuously protected with zero-trust access, automated certificate rotation every eight hours, and high-performance connectivity that keeps security invisible to the user but uncompromising for the business.




