VPN vs Broadband QoE
Many services today are consumed as applications across multiple networks which is why the network matters. The users are accessing these applications from different locations, including home, office, and on the road in coffee shops, hotels, airports, etc., most often over unmanaged networks.
Not all applications the end-user accesses are equal. Every application has its own requirements and expectations from the underlying network.
Where network protocols fit in
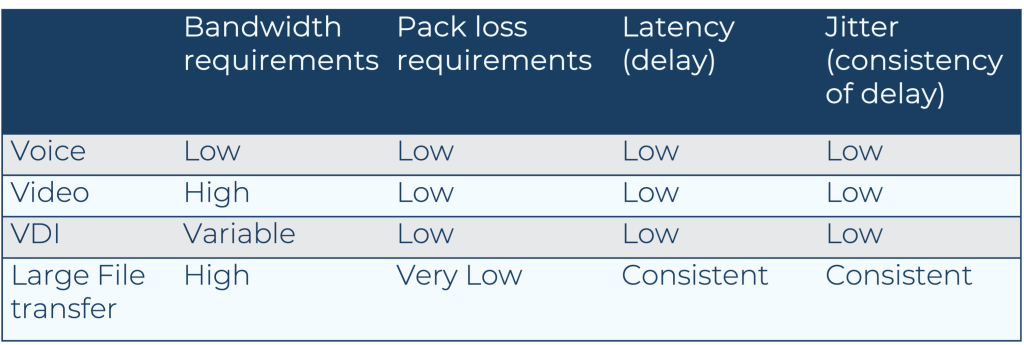
| Bandwidth Requirements | Packet Loss Requirements | Latency (delay) | Jitter (delay variation | |
|---|---|---|---|---|
| Voice | Low | Low | Low | Low |
| Video | High | Low | Low | Low |
| VDI | Variable | Low | Low | Low |
| Large File Transfer | High | Very Low | Low | Medium |
In a typical case, the user’s application traffic traverses multiple network segments (e.g., Wi-Fi/cellular, broadband, mid-mile, etc.) before it reaches the application server.
Each network segment may have its own network characteristics with associated network impairments, for example:
- Wireless including Wi-Fi and cellular: Wireless exhibits burst loss from interference, multipath fading, shadowing, and other signal inhibitors. This can result in low bandwidth and poor coverage, which leads to inconsistent throughput, delay, and jitter. (Wireless propagation fundamentals.)
- Broadband includes technologies such as DSL, cable, fiber, Satellite, and wireless (see above): Broadband suffers from a number of issues, including oversubscription, symmetry, rate limiting on certain ports, and “best effort” reliability and uptime.
- Mid-mile: This suffers from ISP/peering issues that impact loss, path selection, latency, and variable delay

The flow control that is implemented at TCP protocol or at the application layer for UDP-based apps is always end-to-end. This means they can only react to what they can measure or predict, such as a packet loss, delay, or jitter across the end-to-end connection. They do not have the knowledge of why certain network impairments impact certain network segments differently. They will not be able to see if the impairment comes from the user being in a crowded hotspot or if it is a broadband oversubscription issue or if it is congestion in the mid-mile due to peering. Many times, by the time the applications or protocols react based on end-to-end measurements or predictions, the condition has changed. Often it is assumed that the impairments are caused by congestion, which may not always be the case, especially in wireless segments.
The problem with end-to-end protocols
The problem is that remediation measures (e.g., reducing the rate, changing the CODEC, adding FEC, etc.) may, in fact, make the conditions worse. Often this results in applications not being able to utilize the available capacity of the underlying networks. We will show in the next blog how the typical response of TCP with a packet loss of less than half of one percent will reduce the effective throughput of a link by over 95%. That means a 25 megabits-per-second broadband connection that is perfectly capable of supporting video, voice, and file transfers suddenly become effectively a 1.25 megabits-per-second link barely capable of voice.
Since almost every user now accesses their apps and services through a form of wireless network, there will almost always be some packet loss. This makes the ability to overcome this loss and stop the severe impact on the end-user experience paramount for organizations with remote workers.
What is QoE in networking?
What is required is an intelligent overlay that understands the impairments of each network segment and the application requirements and takes adaptive localized actions to “hide” the network impairments from the applications and protocols so the end-to-end flow control does not kick in there, impacting the overall user experience.
Cloudbrink’s Hybrid Access as a Service does exactly that, with an intelligent overlay protocol and FAST edges, which allows the protocol to make localized decisions based on the conditions and type of network being traversed.
Simple packet loss management alone is not sufficient; For example, packets cannot be retried indefinitely, which could increase the effective latency and wastage of bandwidth. More intelligent techniques are required.
We are not claiming that networks are bad all the time. But even on the best of connections, the occasional network impairments are a fact of life. On top of this, Apps are becoming more demanding. Apps require consistent performance from the network. Packet loss and delay may happen occasionally but can have a significant impact on the application performance and user experience.
Cloudbrink’s solution accelerates the network performance adaptively to match the application performance using a variety of techniques together known as Cloudbrink’s preemptive and accelerated packet recovery:
Preemptive techniques such as the following:
- Multipath
- Packet interleaving
- Aggregation
- Piggybacking
- Packet-level FEC
Accelerated recovery techniques:
- Localized and adaptive retransmissions
These techniques are used in an adaptive manner. The methods employed are based on the network segment, app characteristics, and instantaneous network conditions. Through an AI-driven engine, this enables the protocol to rewrite itself to optimize for the particular conditions to recover from packet loss and manage latency and jitter.
While packet loss can be managed with FEC, localized retransmissions, etc. Delay and jitter are also managed through patented interleaving and other techniques.
In our next blog in the series, we will look in more detail at why the network matters and consider the detail of accelerated recovery techniques.
Looking for a fast ZTNA solution that overcomes network issues?
- Check out our ZTNA page.
- Check out our VPN vs ZTNA whitepaper.
- Request a VPN demonstration.